
Conditions, Not Causes
What agentic AI deployment is quietly eroding — and why no one can see it yet

The Moment Before You Understand
Somewhere on the A1 between Bern and Zurich, during the summer roadworks season, the lane markings change. The white lines that have guided every car on that stretch for years are temporarily replaced by orange ones — brighter, more vivid, officially sanctioned, signaling that the geometry ahead has shifted to accommodate the construction zone. Swiss road authorities have been doing this for years. Standard practice, fully regulated, expected by anyone who drives these roads.
Your car is not expecting it.
Not because the system is poorly designed. The orange lines fall at the edge of what it has learned to read. The car hesitates — a fraction of a second, a slight correction that feels different from its usual smoothness. If you are paying attention, you feel it. If you have been paying attention for eighteen months, you are already reaching for the wheel before you have consciously processed why.
If you have been a passenger for those eighteen months, you feel the hesitation too. But the gap between feeling it and knowing what to do with it is wider than it used to be. The conditions for that gap were not created in that moment on the A1. They accumulated gradually, across hundreds of journeys, through the effect of not driving.
This is not a situation about a system failing. It is a situation about the conditions that make failure possible — and about how those conditions become invisible because everything looks fine right up until it doesn’t.
That invisibility is what I want to examine in this post.
The previous two posts explored what happens to practitioners when agency shifts to the system, and what genuine participation in an agentic system requires. Both were concerned with the present tense — what is changing, what it demands of us now.
This post is concerned with what accumulates. Not what participation requires, but what happens when the conditions for genuine participation are absent — quietly, gradually — and a system eventually reaches the edge of its competence. Not the moment of failure itself, but the slow process by which the ground for failure is prepared, without anyone intending it.
One question keeps surfacing as I do. Organizations ask: what roles remain for humans as AI takes on more of the work? A different question sits underneath it: whether the humans filling those roles can actually perform what those roles require. The first is about design. The second is about development. A fitness question sits in that gap — whether the human’s developmental trajectory matches the demands of the operating environment they have been placed in. And that gap is where some of the most consequential things are happening — mostly out of sight.

What Accumulates Before Anyone Notices
A tradition in safety engineering and cognitive systems research — built by David Woods, Erik Hollnagel, Jens Rasmussen, and Sidney Dekker — has been asking this question for decades, under different names: Work-as-Imagined versus Work-as-Done, the knowing-doing gap, espoused theory versus theory-in-use. Different disciplines, different vocabularies, the same underlying observation. What organizations believe is happening and what is actually happening are rarely the same thing.
The gap between them is normal, persistent, and invisible until something surfaces it.
Dekker, building on this tradition, describes a particular failure mode he calls drift into failure. Systems don’t break down suddenly. They drift toward failure conditions through a sequence of decisions that each appear locally rational at the time. No single step is obviously wrong. The accumulation creates the conditions for failure — and the accumulation is invisible because each step looks reasonable from inside the situation.
Dekker developed this for human systems. The extension to agentic AI is my inference, not his. But the structure holds.
A typical agentic AI deployment over eighteen months: a team adopts the system for a category of work. Early outputs are good. Confidence builds. Gradually — not through any single decision, but through the accumulated weight of small ones — human involvement thins. Review cycles lengthen. The harness that was going to be built gets deprioritized against competing demands. The monitoring that was planned becomes passive. Nobody decides to reduce oversight. It reduces itself, through friction and reasonable assumption.
The system is performing well because nothing has gone wrong. Meanwhile the context is quietly diverging from the context the system was given at the start. The informational environment has shifted. The original intent has evolved but the specification hasn’t been updated. The outputs remain plausible — coherent, professional — until they don’t.
This is drift. It is like dropping your guard as things begin to feel normal — as the situation settles into what feels like a safe zone. It has no moment of origin. There is no decision point where someone chose to stop supervising. The supervision thinned the way light changes in the afternoon: gradually, then only obviously in retrospect.
Here is where hindsight bias matters, and where Dekker’s argument is most important to hold. After a failure, everything looks predictable. The signals seem obvious. The decisions seem inexplicable. But from inside the situation, at the moment each decision was made, the signals were not obvious and the decisions were not inexplicable. They were locally rational. The team that stopped reviewing summaries critically did so because the summaries had been good. The organization that thinned its review cycles did so because review cycles are expensive and the system appeared to be performing.
Looking back and saying “they should have known” imports a clarity that was not available at the time. Explainability in hindsight is not the same as accountability in the moment. Post-hoc, we can reconstruct what happened. The harder question — the one that matters for trust — is whether anyone could have accounted for it at the time it was happening.
This matters for how we think about agentic systems acting in the world. When an AI agent makes a decision that appears wrong in retrospect — approving a transaction under conditions that had quietly shifted, continuing a workflow that changed context should have stopped — the useful question is not “why did the agent fail?” but “what conditions made that action appear correct to the system, given its training and inputs at that moment?” The local rationality principle doesn’t translate cleanly from human operators to AI systems — the mechanism is different, the phenomenology entirely different — but the conditions question does. What was the system optimizing for? What had it been trained to treat as normal? What signals would have produced a different output, and were those signals present?
These are not questions about AI error. They are questions about the conditions under which the system was operating.
To understand where those conditions come from, it helps to borrow a distinction from safety engineering: the sharp edge and the blunt edge. The sharp edge is where the work actually happens — where actions are taken, where consequences are immediate, where failure surfaces. In traditional systems, this is the operator: the nurse, the pilot, the air traffic controller in direct contact with the situation. The blunt edge is where the conditions are designed — where decisions about deployment, architecture, constraints, and governance are made, often far from where their consequences appear.
In agentic AI deployment, something significant has shifted. The agent has moved to the sharp edge. The agent is the one taking actions, crossing system boundaries, making calls in real time. The human practitioner has been moved back — to the position of supervisor, director, approver. And the conditions the agent operates within — the harness, the context, the guardrails, the constraints — are the blunt edge. When a harness didn’t prevent a security boundary from being crossed, and the agent crossed it because nothing in its operating conditions said it shouldn’t, the failure surfaced at the sharp edge. But the condition was created at the blunt edge. And the human, now nominally accountable for what happened at the sharp edge, was several steps removed from both.
Hollnagel and Woods’s Work-as-Imagined versus Work-as-Done gives this its sharpest form. The organization imagines a human who reviews outputs, catches drift, exercises judgement at the moments that matter. The work as performed increasingly involves a human who approves outputs at the end of a batch, whose review is necessarily high-level because volume is high and time is short, and whose capacity to exercise the judgement the role imagines has been quietly thinning with every workflow that ran without requiring it.
Hollnagel calls the underlying mechanism the efficiency-thoroughness trade-off — the ETTO principle. Under real conditions, thoroughness is always trading against efficiency, and efficiency usually wins. Not through negligence. Through the rational allocation of limited attention. The ETTO trade-off is not a failure mode. It is how humans and organizations function under pressure — which is precisely why the drift it enables accumulates without anyone choosing to let it.
The orange lines on the A1 are the image for this. The road authority imagines drivers can handle the temporary markings. In most conditions, for most drivers, they can. The gap between Work-as-Imagined and Work-as-Done is narrow enough not to matter. But at the edges — a driver who has not been actively driving for eighteen months, a system trained on white lines encountering orange ones at 120 km/h — the gap opens. And it was always there. It just had nothing to surface it.
Locally rational choices created the conditions for the gap. Nobody at the blunt edge made a wrong decision. The road authority followed standard practice. The system performed within its design parameters. The driver was nominally present and responsible. The conditions simply did not account for each other.
This is what is happening in agentic AI deployment — not in the dramatic cases, but in the ordinary ones, in organizations genuinely trying to get this right.
Five Boundaries, Five Questions
Rasmussen’s dynamic safety model describes something that feels increasingly relevant. Systems operating under real conditions face two competing pressures: the pressure to be economically efficient and the pressure to manage workload. Both push the system toward a third boundary — the boundary of unacceptable failure. The safety margin is not a fixed line. It erodes as the other pressures accumulate. The system drifts toward the boundary not because anyone chose to approach it, but because rational responses to real pressures, repeated over time, move it there.
Extending this to agentic AI — and this extension is mine, not Rasmussen’s — the question becomes: toward which boundary are we drifting, and do we have the means to see it before we breach it?
Not one boundary, but five — each representing a different property an agentic system needs to maintain to be trustworthy over time. They are not equally visible. They are not equally monitored. The pressures eroding them are not symmetric.
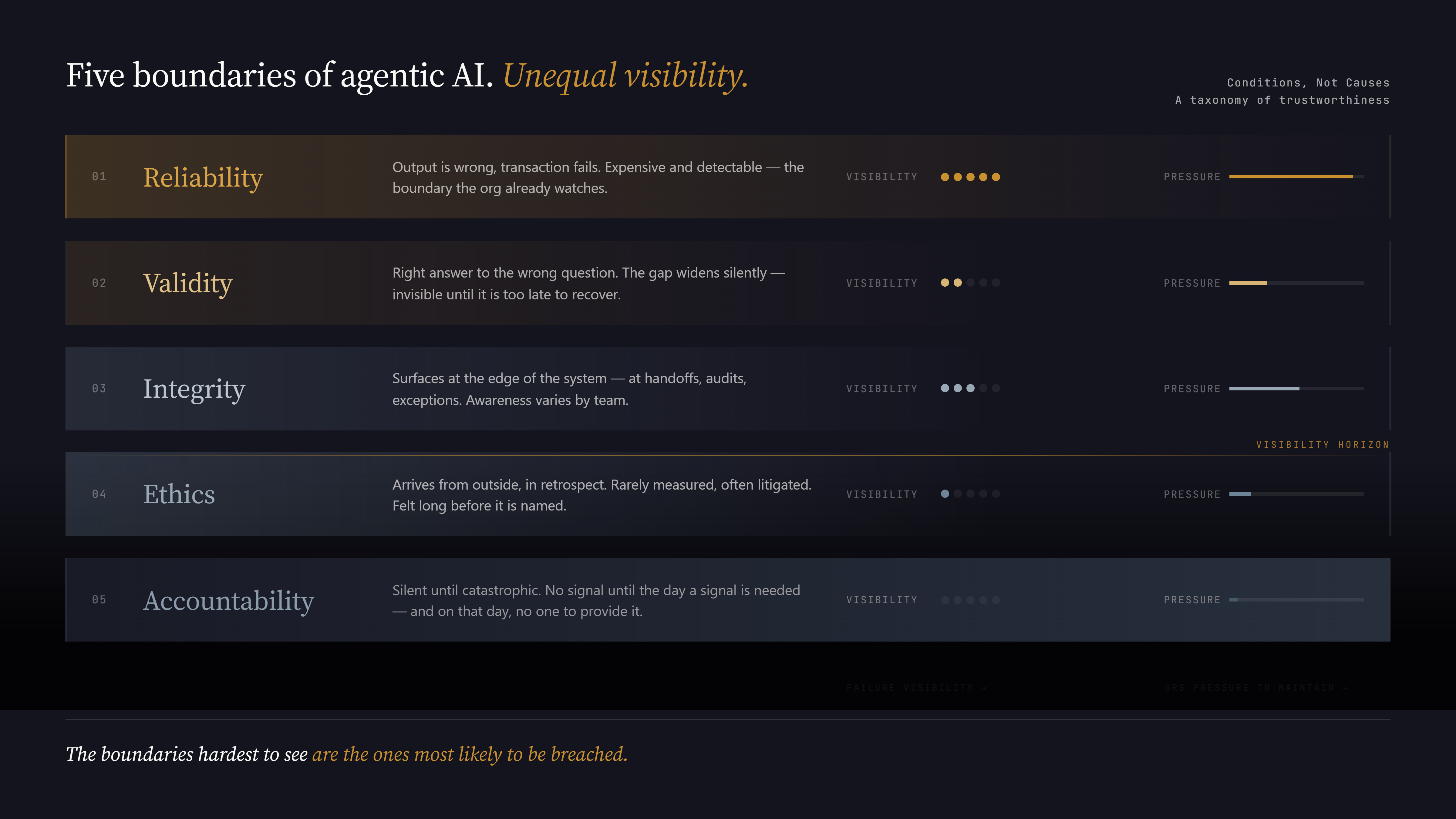
The first is reliability. Does the system produce correct output consistently, across the conditions it was designed to operate in? This is the boundary most organizations are watching. Reliability failures are visible — the output is wrong, the transaction fails. They are expensive, so there is at least some organizational incentive to invest in detection.
The second is validity. A system can be reliable — performing consistently within its training distribution — while failing on validity. The question validity asks is different: does the system’s model of the world still represent the world it is actually operating in? The orange lines are a validity failure. The system behaves consistently. It just behaves consistently in a way that no longer matches the conditions of deployment. The gap between training distribution and deployment reality widens without producing visible errors, until the divergence is wide enough to surface.
The research on what has been called the jagged frontier — from a Harvard Business School study of AI use among consultants — illustrates this well. Consultants using AI performed significantly better on tasks inside the system’s capability frontier, and significantly worse on tasks outside it. The system was not unreliable. It was invalid for those tasks: confidently producing output that looked correct, in conditions where it was not. Practitioners in the approval loop could not catch it, partly because plausible-looking wrong output is hard to distinguish from correct output without the judgement that comes from a genuine practice loop.
The third is integrity. Does the system’s behavior remain aligned with the values and intent of the organization that deployed it — including the intentions never explicitly encoded as constraints? Integrity failures often surface at the edge: in what the system committed to a customer, in what decision it made in a domain where intent existed but guardrails did not. The agent that told a passenger they could apply for a bereavement discount retroactively was not unreliable and not invalid. It operated outside what the organization had authorized, in a space where intent existed but constraints did not.
The fourth is ethics. This boundary is distinct from integrity, and the distinction matters. Integrity is an internal question: does the system match organizational intent? Ethics is an external question: does the system’s behavior hold up against standards broader than what the organization intended?
Consider a financial services firm that deploys an agent to triage customer service requests — prioritizing cases by urgency and value. The system performs reliably and as intended. Integrity is intact. But the prioritization criteria, never examined through an ethical lens, consistently deprioritize vulnerable customers: elderly clients with smaller portfolios, people whose requests are phrased less confidently. The organization’s intent was efficiency. The ethical boundary around fair treatment was never encoded.
What makes this an ethics failure rather than an integrity failure is the mechanism. De Kai — a cognitive scientist whose work spans AI, linguistics, and ethical machine intelligence — describes a tripartite interplay: cognitive bias (how the designers specified the criteria), inductive bias (why any learning system trained on historical data will encode the value judgements implicit in that data — a mathematically unavoidable tendency), and algorithmic bias (which system operationalized those judgements at scale). None of the three is individually the cause. The ethical boundary was breached through their interplay — and that absence of a single traceable cause is what distinguishes an ethics failure from an integrity failure. Ethics resists reduction to a measurable property for this reason: ethical judgement outruns rules, which is why it is most at risk when the humans nominally responsible are in the approval loop rather than the practice loop.
The fifth is accountability. When a consequential decision was made — is there a human who can genuinely account for it? Not nominally responsible, but actually able to explain what the system did, why, and under what conditions, because they were genuinely supervising.
Consider a hospital that has deployed an agentic system to assist with medication dosing for complex cases. Clinicians review and approve its recommendations. An adverse event occurs. The clinical review board asks the attending physician: can you explain the basis for this dosing decision? The physician approved the recommendation. They cannot explain the reasoning — not because they were careless, but because the system had integrated interactions across multiple medications in ways no individual clinician holds in working memory. The physician had not developed the working model of the system’s behavior that would let them identify where it might be overconfident.
The approval was genuine. The understanding behind it was not. In agentic workflows, technical explainability means something specific: audit trails of which tools were called, what data was retrieved, what reasoning steps the agent followed, what decisions triggered what actions. That account can be reconstructed. But it does not answer what the review board is asking: why did a clinician judge this to be safe? That question — the accountability question — requires a human who was genuinely in the loop. Not one who was present and approving.
This is the accountability boundary breached — through the gap between nominal oversight and genuine understanding. Technical explainability can tell you the steps the agent took. It cannot substitute for a practitioner who understood what the system was doing well enough to vouch for it as their own professional judgement.
This connects to Susskind’s moral limits argument: society expects humans to bear moral responsibility for certain consequential decisions — not because humans are better at making them, but because accountability is a social and moral category. The accountability boundary is not only an operational concern. It is a structural feature of how we have organized moral responsibility. And if the humans nominally bearing that responsibility are in the approval loop — present but not genuinely supervising — then the moral limit Susskind identifies is not being maintained. It is being performed.
“Responsible AI has the vocabulary. Safety engineering has the dynamics. Neither alone is sufficient.”
Responsible AI discourse tends to treat these five properties as design-time requirements — things to be built in at the start of a deployment. The drift argument says otherwise. The parallel to software engineering is apt: compile-time checks catch what you can anticipate; runtime governance is what catches what you can’t. These five boundaries require active maintenance under changing conditions. Reliability erodes when the system is pushed beyond its design envelope. Validity erodes when deployment conditions diverge from training conditions. Integrity erodes when the organization’s intent evolves but constraints don’t follow. Ethics erodes when practitioners lose the judgement to recognize an ethical boundary being approached. Accountability erodes when the humans in the loop gradually lose the working knowledge of what the system is doing and why.
The pressure structure is asymmetric. Reliability failures are visible and costly. Validity failures are invisible until the gap surfaces. Integrity failures may not surface internally at all. Ethical failures often become visible only through consequences arriving from outside. Accountability failures are the most insidious: costless and invisible until catastrophically needed.
What Seeing the Drift Requires
A thread runs through the previous sections that hasn’t yet been named directly. The drift accumulates invisibly. The five boundaries erode without producing signals that standard review processes pick up. The Work-as-Imagined gap widens without anyone registering it as a gap. What would it actually take to see the drift before it becomes a breach?
Gary Klein’s research on expert decision-making offers one answer — partial, but important. Klein studied firefighters, military commanders, intensive care nurses: people who make high-stakes decisions under time pressure and uncertainty. Experts don’t decide by evaluating options. They recognize. Before conscious analysis begins, something in accumulated experience tells them what kind of situation this is, what matters, what is off. He calls this recognition-primed judgement — a pattern library built through thousands of encounters with real situations, real feedback, real consequences.
The critical word is real. That judgement forms through direct encounter with the material — through the kind of sustained engagement the earlier posts described as the practice loop. The firefighter who knows, before they can say why, that this fire is behaving differently — that knowledge was built through fires, not through fire reports. The intensive care nurse who senses that a patient’s condition is changing before any monitor has registered the shift — that knowledge was built through patients, not through patient records. The experienced risk analyst who reads a model’s output and notices something that doesn’t sit right, before they can articulate why — that knowledge was built through the work itself.
These three terms — working model, felt knowledge, recognition-primed judgement — describe related but distinct things. The working model is the cognitive structure: the practitioner’s accumulated understanding of how the system behaves, where it tends to go wrong, what conditions produce what outputs. Felt knowledge is the phenomenology of having it: the sense that something is off before it can be articulated. Recognition-primed judgement is Klein’s formal term for what happens when that felt knowledge is activated — the rapid pattern-match that precedes conscious reasoning. They are not synonyms. They are stages: the working model enables the felt knowledge; the felt knowledge activates recognition-primed judgement.
Weak signal detection is what this capacity produces. Not the obvious signals — the output that is clearly wrong, the reliability breach that surfaces in the dashboard. The weak signals: the slight hesitation in the system’s output that feels different without being obviously incorrect, the small inconsistency in a report that sits wrong with someone who knows the domain deeply, the moment when the orange lines appear and the experienced driver is already reaching for the wheel before they have consciously processed why.
Weak signals do not announce themselves. They are available only to the practitioner who has developed enough felt knowledge to notice that something has changed. That felt knowledge is not transmitted through documentation. It forms through the practice loop, through sustained encounter with the system’s actual behavior, through the gradual accumulation of pattern recognition Klein’s research describes. You need, as I think of it, an eye for an I — for the indicators, the weak signals, the slight anomalies that only become visible to the practitioner who has developed the felt knowledge to notice them. Klein’s book is titled Seeing What Others Don’t. That capacity is what is at stake.

Without that working model, that felt knowledge, reliability failures are visible. Integrity failures may be caught by someone who knows the domain well enough. But validity failures, ethical boundary approaches, and accountability erosion are the weak signal territory. They do not announce themselves.
An uncomfortable implication follows. The organizations moving fastest toward human-led, agent-operated workflows are systematically reducing the conditions under which that felt knowledge forms. The efficiency gains from agentic AI are real. The case for moving fast is not irrational. But the capacity being eroded is invisible in any productivity metric. You cannot measure the weak signal detection capacity a practitioner is failing to develop, because they are not detecting the signals they are not equipped to detect.
The driving instructor scenario is instructive here — from a different angle than the opening. The question is not just whether the student can still drive. It is what good driving means when the car handles most of what driving used to require. The benchmark shifts. If the instructor keeps teaching to the old standard while the new standard goes unaddressed, they produce students who can pass the old test and cannot perform the new function.
Organizations are in the same position. They are designing roles, assessing performance, and building development programs to a standard quietly becoming obsolete — while the new standard, the capacity for genuine supervision of agentic systems, goes unmeasured and undeveloped. Through the absence of structural attention.
The Question Organizations Are Not Asking
Susskind’s careful analysis of what will remain for humans to do as AI capabilities expand arrives at three limits — comparative advantage, preference, and moral limits — and answers a real question: what tasks remain? But it is silent on the developmental question that sits underneath it: whether the humans assigned to those tasks are capable of performing them.
This is the structural/developmental gap beneath the surface of most AI workforce planning. Structural thinking describes the demand side: what roles are needed, what functions persist. Necessary and serious. But silent on the supply side: whether the humans filling those roles have the capability those roles require, and whether the conditions for developing that capability are being maintained or eroded.
The gap between those two questions is not a gap in the literature. It is a gap in practice.
Microsoft’s 2026 Work Trend Index contains a finding worth sitting with: 43% of its most advanced AI adopters deliberately do some tasks without AI assistance to keep their skills sharp. More than half intentionally pause before starting work to decide what a human should handle versus what AI should. These are not people following a policy. They are practitioners who have intuitively grasped the developmental problem — who understand that the practice loop matters and needs protecting.
The finding is striking because it is individual. These practitioners have worked it out against the grain of organizational pressure. They are preserving the conditions for weak signal detection through personal discipline, not through structural design. If 43% of the most advanced adopters feel the need to do this, the implication for the less advanced — and for organizations that have not yet asked the question — is worth holding.
What would it look like for organizations to ask the developmental question structurally, not just individually? Not a prescription — the conditions are too varied, the deployments too different, for a checklist to be honest. But some directions suggest themselves. Are practitioners developing a working model of the system’s characteristic behavior, or only familiarity with its outputs? Are review processes designed to surface weak signals, or only to catch reliability failures? Are development programs teaching to the old standard, or to the new one — the capacity for genuine supervision of systems that act on your behalf?
These are not questions that have standard answers. They are questions that, in most organizations, are not yet being asked at all. The structural question — how do we organize around AI? — has been answered, or is being answered at speed. The developmental question is still, largely, invisible.
“The drift into failure is not a future risk. For many organizations deploying agentic AI at scale today, it is already underway.”
The drift into failure is not a future risk. For many organizations deploying agentic AI at scale today, it is already underway — in the thinning of review cycles, in the harnesses not built, in the practice loops not running, in the five boundaries being approached without the mechanisms to see them being approached.
What would it take to see it? The same thing it has always taken to see what others can’t: a practice loop that is still running, a felt knowledge of the system’s actual behavior, a judgement developed through encounter rather than through approval. The conditions, in other words, that the drift has been quietly eroding.
“That is where we are. Not at the moment of failure. At the moment before you understand.”
That is where we are. Not at the moment of failure. At the moment before you understand.
Notes and References
The safety engineering and cognitive systems tradition The Work-as-Imagined versus Work-as-Done distinction is most fully developed in Erik Hollnagel’s resilience engineering work. A useful primary source is: Erik Hollnagel, The ETTO Principle: Efficiency-Thoroughness Trade-Off: Why Things That Go Right Sometimes Go Wrong (Ashgate, 2009). The ETTO principle — that under real conditions, thoroughness is always trading against efficiency — is developed extensively here, with Hollnagel arguing that this trade-off is not a failure mode but a normal feature of performance under pressure. David Woods’s contributions to the cognitive systems engineering tradition are substantial and underacknowledged in popular accounts; his collaborative work with Hollnagel and others on joint cognitive systems and resilience engineering forms the intellectual foundation for much of what Dekker later made accessible to wider audiences.
Jens Rasmussen — Risk management in a dynamic society Jens Rasmussen, “Risk management in a dynamic society: a modelling problem,” Safety Science, 27(2–3), pp. 183–213 (1997). The paper that introduced the dynamic safety model and the boundary framework used in this post. The extension of this model to agentic AI deployment is the author’s own inference, not Rasmussen’s.
Sidney Dekker — Drift into Failure Sidney Dekker, Drift into Failure: From Hunting Broken Components to Understanding Complex Systems (Ashgate, 2011; also CRC Press, 2016). Dekker’s central argument: complex systems fail not through component breakdown or individual error, but through the gradual accumulation of conditions that each appear locally rational. His concept of the “local rationality principle” is applied in this post to agentic AI systems, with the caveat that the mechanism differs between human operators and AI agents. Dekker’s sharp/blunt edge distinction appears throughout his work including The Field Guide to Understanding Human Error (Ashgate, 2002; 3rd edition, CRC Press, 2014).
Gary Klein — Recognition-primed decision making and Seeing What Others Don’t Gary Klein, Sources of Power: How People Make Decisions (MIT Press, 1998; 20th Anniversary Edition, 2017) — the foundational text on recognition-primed decision making and naturalized judgment. Gary Klein, Seeing What Others Don’t: The Remarkable Ways We Gain Insights (PublicAffairs, 2013) — the source of the title reference in this post.
The jagged frontier — Dell’Acqua et al. Fabrizio Dell’Acqua et al., “Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of Artificial Intelligence on Knowledge Worker Productivity and Quality,” Organization Science, 37(2): 403–423 (March 2026; first released as SSRN working paper, September 2023). The persuasion escalation finding comes from: Steven Randazzo et al., “GenAI as a Power Persuader: How Professionals Get Persuasion Bombed When They Attempt to Validate LLMs,” Harvard Business School Working Paper 26-021.
Daniel Susskind — What Will Remain for People to Do? Daniel Susskind, “What Will Remain for People to Do?”, Knight First Amendment Institute at Columbia University, Working Paper 25-08 (April 7, 2025). Available at knightcolumbia.org.
De Kai — Raising AI and the tripartite bias framework De Kai, Raising AI: An Essential Guide to Parenting Our Future (MIT Press, 2025). The Why/Who/How framing — cognitive bias as How, inductive bias as Why, algorithmic bias as Who — is the author’s own synthesis of De Kai’s framework with the conditions argument of this post. De Kai’s book references inductive biases at p. 84 and throughout.
Microsoft Work Trend Index 2025 and 2026 Microsoft, 2025 Work Trend Index Annual Report: The Year the Frontier Firm Is Born (Microsoft Corporation, 2025). Microsoft, 2026 Work Trend Index Annual Report (Microsoft Corporation, 2026). The 43% figure comes from the 2026 report. WTI statistics are self-reported survey signals treated here as directional indicators, not precise empirical claims.
Air Canada bereavement discount case Adjudicated by Canada’s Civil Resolution Tribunal, February 2024. Public record.
Series context This post is the third in a series on At Adjacent Possible (atadjacentpossible.substack.com). Passenger in the Driver’s Seat introduced the practice loop, the approval loop, and the agent/actant distinction. Watching Is Not Supervising developed the conditions required for genuine participation in an agentic system.